Scalable 3D Deep Learning: Methods and Applications
Abstract
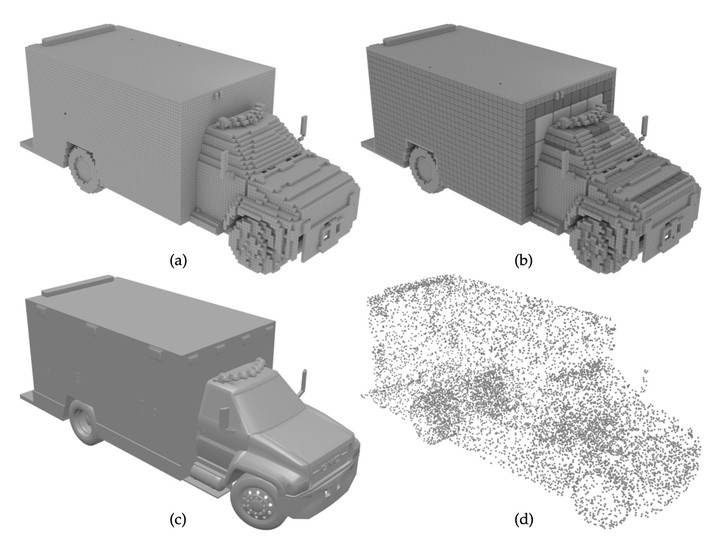
In recent years, deep convolutional neural networks (CNNs) have achieved remarkable success in most 2D image processing tasks. Still, the direct processing of 3D data, not only their 2D projections, is required in many applications. Naive extensions of 2D deep learning techniques into 3D rely on voxel grids which are inefficient due to their cubic complexity and thus only support prohibitively low resolutions. Therefore, it is crucially important to develop dedicated 3D deep learning algorithms that operate on efficient 3D representations like point clouds and octrees. The algorithm design depends on the task type: in analysis tasks the 3D geometry is given as input and needs to be processed efficiently, while in synthesis tasks the 3D geometry has to be generated from an abstract representation. The first part of this thesis proposes methods for both efficient analysis and synthesis of 3D data using CNNs. In case of analysis, we focus on the task of semantic segmentation of 3D scenes represented as point clouds. We propose a new construct - tangent convolution - which operates directly on surfaces and can be used to build efficient CNNs. We apply networks that use tangent convolutions to large-scale semantic segmentation of real-world indoor and outdoor datasets. For synthesis, we propose a novel convolutional decoder for generating 3D shapes represented as octrees. Our approach is significantly more efficient than CNNs based on dense voxel grids, both in memory consumption and in computation time. This enables the generation of high-resolution 3D shapes. We validate the proposed method on three different tasks, including shape auto-encoding, generating shapes from high-level information, and single-view 3D reconstruction. The second part of the thesis is devoted to the problem of single-view 3D reconstruction; in particular, to a realistic analysis of its current state. Many recent CNN-based methods for solving this task focus on developing dedicated decoders for different 3D representations. We systematically analyze these methods comparing them with two custom baselines which internally rely on image classification and retrieval, i.e. which solve a recognition problem. The results of these simple decoder-less baselines are statistically indistinguishable from more sophisticated state-of-the-art networks, indicating that the latter also rely mostly on recognition. We formulate the problems in the widely adopted experimental setup that lead to such behavior and outline possible solutions. Finally, we extensively study how well existing single-view 3D reconstruction methods which are trained on synthetic data, generalize to real-world images. For this, we collected a new dataset of objects of various shapes with fine-grained control over their appearance. We observe that, despite being trained on realistic renderings and a multitude of objects, state-of-the-art methods still struggle to generalize to real-world images. Our analysis also indicates the benefit of introducing more structure into the computational pipeline via making an intermediate geometric representation part of its design.